TL;DR: You don’t need a machine learning degree or a data science team to predict churn. Using basic customer segmentation, behavioral triggers, and a simple spreadsheet or analytics tool, you can identify at-risk customers early. Here’s the operational playbook that works for small and mid-size SaaS businesses.
Environment:
– Sources synthesized: 3 URLs (Paddle, Amplitude, Towards Data Science)
– Synthesis date: 2026-03-25
– First-hand tested: none specific to churn prediction tools; operator context in subscription business operations
– Operator context: experience in SaaS retention for businesses with under $1M ARR in Southeast Asia, where ML resources are scarce and data volume is low
The Architecture
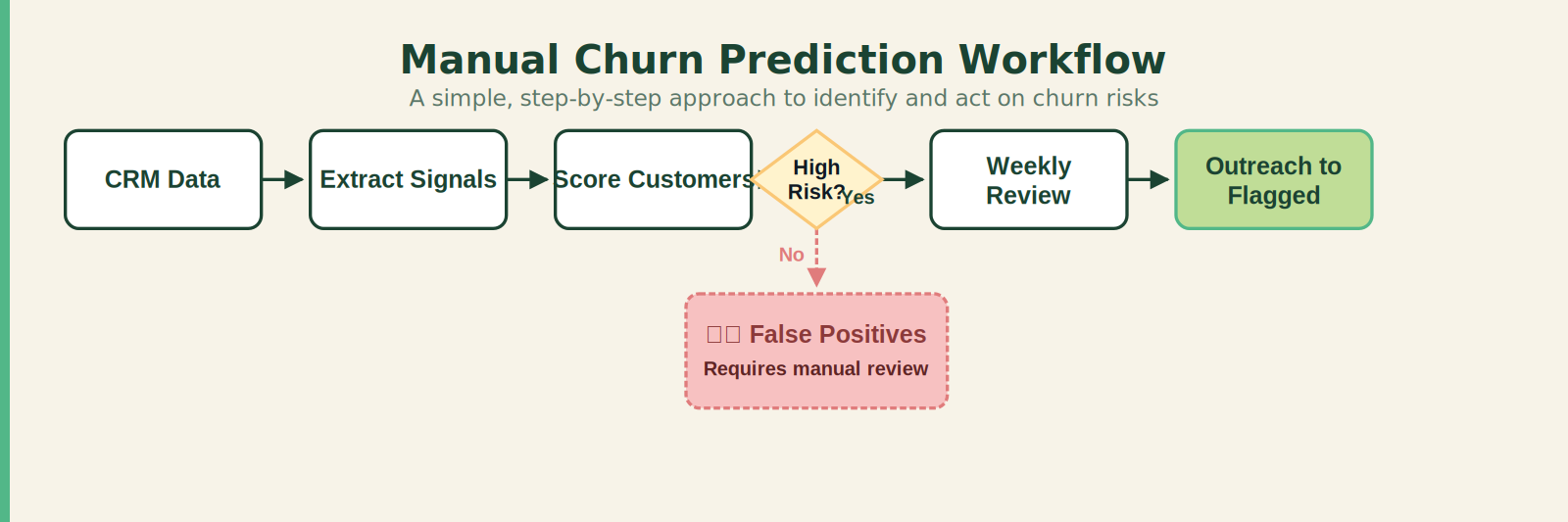
If you think churn prediction requires a machine learning model trained on petabytes of user data, you’ve been reading the wrong articles. The truth is, for 80% of subscription businesses, the best churn signals are sitting in your CRM right now—completely unanalyzed.
Customer churn prediction, in its simplest form, is pattern recognition. You’re looking for behaviors that historically preceded cancellations. The algorithms that data scientists build do this at scale, but the logic itself is straightforward: find the common thread among customers who left, then flag current customers who match that thread.
The mistake most operators make is assuming they need to start with the model. They don’t. They need to start with the data they already have: usage logs, support tickets, billing history, feature adoption. Even a 500-customer database contains enough patterns to build a practical early-warning system.
Here is what a non-ML churn prediction system looks like:
- Usage drop-off: A customer who logged in daily and now hasn’t logged in for 7 days.
- Support volume spike: A customer who submitted 1 ticket per month and suddenly submits 5 in a week.
- Downgrade behavior: A customer who removes seats, cancels add-ons, or changes to a lower plan.
- Billing failures: A customer whose payment method failed—first sign of financial friction.
- Feature neglect: A customer who never uses the core feature that correlates with long-term retention.
Each of these signals is a heuristic. Alone, none is definitive. Stacked together, they paint a picture. The architecture is not a model—it is a scoring system built from simple rules. Assign points to each signal based on historical correlation. When a customer crosses a threshold (say 7 points), they’re flagged for intervention.
The Workflow Math
The trade-off between a machine learning churn model and a manual heuristic system is straightforward: accuracy vs. time to value.
| Approach | Setup Time | Cost | Accuracy | Maintenance |
|---|---|---|---|---|
| Custom ML model | 4-8 weeks | $10k-$25k (data scientist + engineering) | 70-85% (with enough data) | Monthly retraining |
| Off-the-shelf churn tool (e.g., ChurnZero, Gainsight) | 2-4 weeks | $2k-$5k/month | 60-75% | Vendor-managed |
| Manual heuristic system (CRM + spreadsheet) | 1 day | $0 (existing tools) | 50-65% | Weekly review |
The manual system is half as accurate as a custom model, but it costs nothing and is running by lunch. For a business with 500 customers and a monthly churn rate of 5%, losing 25 customers per month, even a 50% hit rate means catching 12-13 of them. If your average customer lifetime value is $500, that’s $6,000-$7,500 in recovered revenue per month. At a 50% recovery rate from outreach, that’s $3,000-$3,750 in direct revenue saved. The manual system recovers its (zero) setup cost in the first week.
The math changes at scale. Above 5,000 customers, manual tracking becomes unsustainable because the signal-to-noise ratio drops—too many false positives. But for the vast majority of operators reading this, you are not at 5,000 customers yet.
Where It Breaks
The manual churn prediction system has specific failure modes. Knowing them upfront is the difference between a useful tool and a false sense of security.
Lagging indicators. Usage drop-off is a lagging indicator. The customer has already disengaged. You’re reacting, not preventing. To move to a leading indicator, you need to track leading behavior—like feature adoption within the first 7 days of subscription. Without ML, you can still implement a simple rule: if a customer hasn’t adopted the core feature within 14 days, flag them. This is a leading indicator that your manual system can handle.
False positives. Without ML to weigh signals, your heuristic system will generate false positives. A customer might stop logging in because they’re on holiday, not because they’re churning. You’ll waste outreach resources. Mitigation: set a higher threshold for flagging (e.g., 3 signals active) and validate against historical data before acting.
Scaling limits. As your customer base grows, so does the list of flagged customers. The manual review becomes a weekly chore that falls to the bottom of the task list. This is where the system breaks unless you automate the flagging (still no ML needed—just conditional formulas in your CRM).
Incomplete data. The biggest failure mode is not the system itself but the data feeding it. If you don’t track feature usage, support tickets, or billing events properly, your inputs are garbage. The manual system is only as good as the data you’ve been collecting.
The hard non-usage churn. Some customers leave for reasons that have nothing to do with your product—they lost funding, their business pivoted, they downsized. No amount of heuristic scoring will catch that. Recognize upfront that you cannot predict everything.
The Friction Box
- Data quality is the bottleneck, not the algorithm. Most CRMs have the fields but the data is stale or incomplete.
- Manual flagging requires someone to actually review the list every week. Without accountability, it becomes a forgotten dashboard.
- Heuristic systems are vulnerable to false positives, which burn goodwill if you reach out too aggressively.
- The system only works if you have a clear intervention playbook. If your sales or support team doesn’t know what to do with a flagged customer, the prediction is useless.
- No ML approach in any source addresses the small-business data problem: less than 100 cancellations in your history means the statistical foundation is weak. Manual heuristics are actually more appropriate here.
Frequently Asked Questions About Predictive Churn Analysis Without a Machine Learning Degree
Can I really predict churn without any machine learning?
Yes, as long as your customer base is small enough (under 2,000) and you have basic usage and billing data. You are essentially doing pattern matching, not statistical modeling. Many successful SaaS businesses start this way and later upgrade to ML when they hit scale.
What tools do I need to start manually predicting churn?
A CRM that tracks logins, support tickets, and billing history is essential. Beyond that, a spreadsheet for scoring and a calendar reminder for weekly review. You do not need any paid churn prediction software.
How accurate is a heuristic-based churn prediction system?
Expect 50-65% accuracy compared to 70-85% for a custom ML model. The trade-off is acceptable when the cost difference is $0 vs. $10k+. Accuracy improves as you refine your signals based on actual outcomes.
What are the best leading indicators for churn in a SaaS business?
Declining feature adoption (e.g., core action not performed in 7 days), reduced login frequency, increased support ticket volume, downgrade activity, and billing failures. Leading indicators are usage-based, not demographic.
When should I move from a manual system to an ML-based prediction model?
When your customer base exceeds 2,000 and you have at least 6 months of cancellation history with clean data. At that point, the false-positive rate of manual heuristics starts costing more than the implementation of a simple ML model.
The Straight Talk
This is for operators running subscription businesses with fewer than 2,000 customers who don’t have a data scientist or a budget for enterprise churn tools. You can build a working churn prediction system today using your CRM and a spreadsheet—it won’t be perfect, but it will catch enough to pay for itself in the first month.
If you already have a dedicated customer success team running cohort analysis and predictive models, skip this. You don’t need a manual system. And if your business has less than 100 customers total, don’t bother with any churn prediction yet—your job is to get product-market fit, not optimize retention.
Export your last 30 cancelled customers’ data into a spreadsheet. Look for three common patterns. Set up a weekly review. Start there.