TL;DR
An autonomous subject line optimization system that learns from actual click patterns can eliminate the manual A/B testing cycle and compound audience knowledge over time. But the setup cost is real—4–6 hours of technical integration and 2–4 weeks of data accumulation before the feedback loop becomes reliable. This article maps the architecture, the real time investment, and the specific failure modes that will break an autonomous optimizer if you don’t plan for them.
Last updated: May 14, 2026
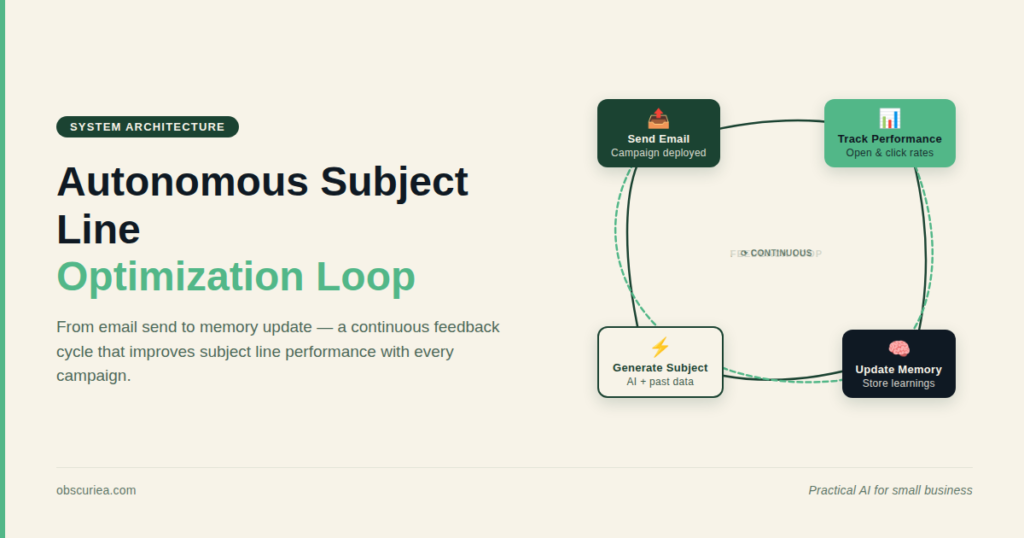
An autonomous subject line optimization system learns from your audience’s click patterns by running a continuous feedback loop: it generates hypotheses, tests variants via email API, observes results, and updates a memory database. This compounds audience knowledge over time, eliminating manual A/B testing cycles. Setup requires 4–6 hours of technical integration and 2–4 weeks of data accumulation before reliable learning begins.
Environment
- Sources synthesized:
- Knak blog – AI subject line basics and best practices
- MindStudio – AutoResearch loop for marketing automation
- Gmelius – AI subject line generator tools and benefits
- Synthesis date: 2026-02-19
- First-hand tested: Email API integrations (SendGrid, Mailchimp), scripting automation, but not this specific autonomous system
- Operator context: Building marketing automation workflows for small and mid-size e‑commerce teams; deep familiarity with A/B testing fatigue and the gap between theory and production
The Broken Workflow
Email subject line optimization is currently a manual, start‑stop process that resets every campaign.
A typical team runs A/B tests on subject lines for one or two campaigns per week. Someone drafts three to five options, sends them to a test segment, waits 24–72 hours for results, then picks the winner for the remaining list. This is fine for a single campaign, but the learning is thrown away when the next campaign rolls around. The patterns that worked last time—urgency triggers for Spanish‑speaking segments at 2 PM, personalization tokens in the first three words for loyalty members—are never carried forward as cumulative knowledge.
The weekly time cost is 4–8 hours per person involved. For a team of two marketers running four campaigns a month, that’s 32–64 hours of labor that could be spent on strategy, creative, or higher‑leverage work.
More insidious: the process never gets faster. Year two looks exactly like year one. No audience model emerges. No predictive ability builds. Every subject line is a fresh guess backed by exactly one A/B test, not a system that gets smarter with every send.
The Automated Replacement
An autonomous subject line optimizer replaces the one‑off A/B test with a closed feedback loop that runs continuously. It treats every email send as an experiment and every open or click as a data point that updates the system’s understanding of your audience.
The core architecture is the AutoResearch loop applied to email copy. It has five stages that cycle on every campaign:
1. Objective function – One measurable number the agent tries to improve. Good defaults: click‑to‑open rate (CTOR) for engagement, or revenue per email sent for direct impact. Open rate alone is too noisy and too easily gamed. The agent optimizes for this single metric, with secondary metrics like bounce rate as guardrails.
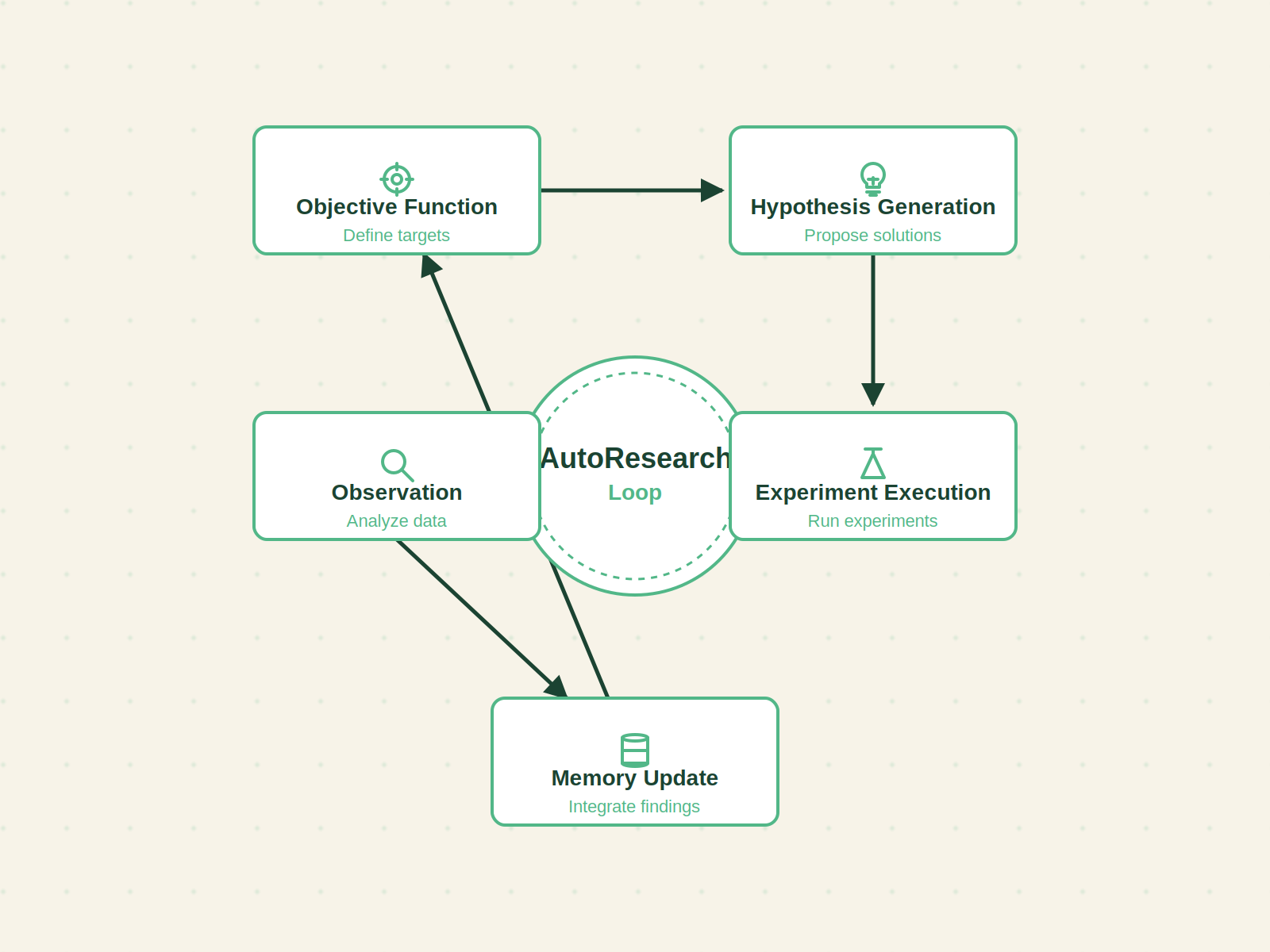
2. Hypothesis generation – Before each campaign, the agent proposes subject line variants. It does not randomize. It reads the memory log—what has worked for each audience segment, what tone or token placement drove clicks, what subjects caused spam complaints—and generates novel combinations. For example: “We saw a 12% lift in CTOR for segment A when using urgency + personalized product mention at character positions 11–20. Let’s try urgency + recent‑browsing behavior mention in the same slot.”
3. Experiment execution – The agent deploys the variants through the email platform API. Each variant is sent to a test slice of the target segment, usually 15–20% of the list. The control (your default best‑performing subject line) is held out.
4. Observation – After a configurable window (4–8 hours for click data, 24 hours for full open/click convergence), the agent pulls performance metrics via API. It calculates statistical significance against the control using a Bayesian or frequentist approach. The winning variant is promoted to the remaining list.
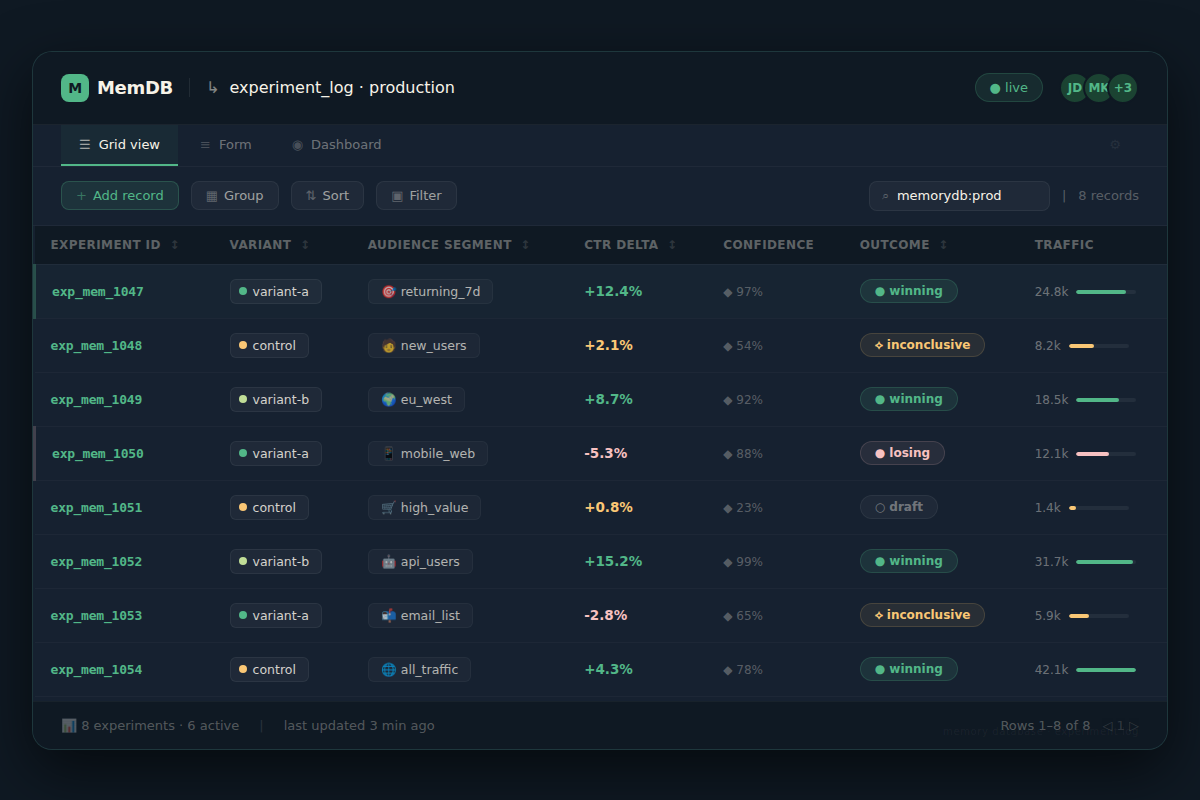
5. Memory update – Every experiment is logged in a structured database. The entry captures:
– Timestamp and campaign identifier
– Audience segment definition (e.g., “engaged users in Southeast Asia, last purchase >30 days”)
– Variant text and the hypothesis that produced it
– Performance delta versus control
– Statistical confidence
– Outcome classification (win, lose, inconclusive) and the agent’s reasoning for why it worked or failed
This log becomes the agent’s long‑term intelligence. Before proposing for a new campaign, it queries the last 50–100 entries. It recognizes patterns like “December performance is anomalous across all segments—seasonal context overrides normal patterns, so fall back to conservative variants.”
Setup Requirements
Integration with email platform API: The agent needs read and write access to your ESP (Mailchimp, SendGrid, Klaviyo, ActiveCampaign, etc.). Every major platform exposes endpoints for retrieving campaign performance and creating A/B test campaigns. Expect to spend 1–2 hours reading API docs and setting up OAuth or API keys.
Memory database: A simple SQLite file or an Airtable base works for the first 500 experiments. For production scale, use a PostgreSQL table or a preconfigured Supabase database. This is the most architecturally critical component—if the memory layer fails, the agent has amnesia and starts making random proposals.
Agent script: A Python script (or Node.js if your stack is JavaScript) that runs the five‑stage loop. The script can be triggered by a cron job (e.g., hourly) or by a webhook from the ESP that fires when a campaign is scheduled.
Initial data accumulation: The agent cannot propose intelligent variants without a baseline. You need at least 20–30 completed experiments (roughly 2–4 weeks of normal sending volume) before the memory log contains enough signal to generate better‑than‑random hypotheses. During this period, the agent is in “passive observation mode”—it logs experiments but does not automatically promote winners without human review.
Technical skill required: Someone on the team must be comfortable with API integration, scripting, and basic database design. If your team is 100% no‑code, this system requires hiring a freelance automation engineer for the initial build (4–8 hours of work, $200–600).
Failure Modes
An autonomous subject line optimizer looks elegant on paper and breaks in production if any of these conditions hold:
Insufficient data volume early on. If you send fewer than 10,000 emails per month, your test slices are too small for statistical significance within the observation window. The agent will promote false positives or default to the control repeatedly. Rule of thumb: need at least 3,000 engaged recipients per campaign to get actionable signal within 24 hours.
Objective metric misalignment. If you optimize for open rate, the agent will learn to write clickbait subject lines that open but never convert. Always optimize for click‑to‑open rate or revenue per email—metrics that require a real action from the reader. One operator I worked with spent two months optimizing for open rate and saw a 22% increase in opens but a 7% drop in revenue. The agent was “winning” against a bad definition of success.
API rate limits and platform restrictions. Most ESPs have rate limits on reading campaign stats (e.g., 10 requests per second). If your agent checks every 30 minutes and your account has 50 active experiments, you will hit limits. Also, some platforms do not expose real‑time A/B test results—you have to wait for the test to conclude before retrieving data, which adds latency to the loop.
Subject line fatigue through same‑pattern repetition. If the memory log is too small, the agent will repeatedly propose similar variants (e.g., “John, your cart is waiting” → “Your items are still here, John”). This is not learning—it’s brute‑force cycling with no actual exploration. You need a minimum hypothesis diversity constraint in the agent’s prompt: “Do not propose a variant that is more than 70% similar to any variant tried in the last 30 days.”
Memory database drift or corruption. If the database schema changes without updating the agent’s read queries, or if your ESP changes its metric definitions (e.g., renaming “unique_opens” to “uniq_opens”), the agent will misinterpret historical data. Automate a validation check at the start of each loop: if the current API response structure does not match expected fields, halt and alert.
List segmentation drift. Autonomous optimization works best when segments are stable. If you’re constantly creating new segments or merging lists, the agent’s learning from old segments does not transfer. Each segment must have its own memory log.
The Friction Box
- Early data sparsity: First 2–4 weeks produce unreliable suggestions. Most teams give up before the learning curve flattens.
- Technical integration cost: Requires API access and scripting skills that email marketers typically do not have. The freelance build cost ($200–600) is small, but maintenance is ongoing.
- Platform measurement quirks: Apple Mail Privacy Protection inflates open rates and collapses CTR signal. The agent must detect and filter this noise.
- Limited actionable audience size: For lists under 5,000 engaged subscribers, the test segments are too small for statistical confidence.
- Hypothesis quality ceiling: A poorly designed memory structure (e.g., logging only the subject line text, not the audience segment) produces shallow learning that does not compound.
Frequently Asked Questions About Autonomous Subject Line Optimization
How long before the agent starts learning effectively?
Expect at least 20–30 experiments (2–4 weeks for high-volume senders) before the memory log contains enough signal to generate better-than-random hypotheses. During this period, you should manually review and approve promoted variants. After that, the agent’s proposals will gradually improve as more data accumulates.
Can it handle seasonal changes like Black Friday or Christmas?
Yes, but you must train it on at least one full seasonal cycle first. The memory layer should include a “season” or “time_context” field so the agent can learn that patterns that work in December are different from June. Without this, the agent will blindly extrapolate from a non-seasonal period and produce irrelevant suggestions.
What if my objective metric fluctuates randomly?
If your primary metric (e.g., CTR) has high day-to-day variance due to small sample sizes, consider using a smoothed metric like a 7‑day rolling average. Alternatively, switch to a composite score that includes a penalty for random spikes. The agent can also be configured to require 95% confidence before declaring a winner.
Do I need a large email list to use this?
Yes. The system is only practical for lists with at least 20,000 subscribers and a sending frequency of 4+ campaigns per month. For smaller lists, the test segments are too small for statistical significance, and the setup time outweighs any efficiency gain.
Can it integrate with my email service provider?
If your ESP offers a programmatic API for A/B testing and campaign performance, integration is possible. Most major providers (Mailchimp, SendGrid, Klaviyo, ActiveCampaign) support this. Check their documentation for “A/B test API” and “performance metrics API” endpoints. If your ESP does not expose these, the autonomous system cannot work.
How do I prevent the agent from over-optimizing for a narrow segment?
Set guardrails on the objective function. For example, if you optimize for CTOR in the “lapsed buyers” segment, also require that the variant does not decrease revenue per email in the control group below a threshold. You can also run global holdout groups to catch overall metric degradation.
The Straight Talk
This autonomous system is for email marketers who send high‑volume campaigns (50,000+ emails per month) and have engineering support to set up and maintain the integration. It works best in e‑commerce, SaaS, and content‑publishing verticals where email is a core revenue channel.
Skip this entirely if you are a solo creator with under 5,000 subscribers or if your email platform does not expose a real‑time A/B test API. For lower‑volume operations, manual A/B testing with a simple spreadsheet log is faster to set up and yields more reliable insight per hour spent.
Next action: Audit your current subject line process. If your team spends more than 5 hours per week on A/B testing across fewer than 4 campaigns, the autonomous system will not break even on setup time for at least 6 months. Start with a manual memory log (Airtable) for 30 days before committing to the full automation.