Choosing the Right Knowledge Base Architecture for Your AI Agent
TL;DR
Most businesses selecting a knowledge base for their AI agent pick the wrong architecture — not because the tools are bad, but because no one has established a decision framework that maps operational requirements to architectural patterns. This article provides that framework. You get a practical comparison of the six emerging architectures, the math behind each choice, and the failure conditions that derail most implementations.
Environment
- Sources synthesized: 3 URLs (The New Stack agentic patterns, Slack AI Knowledge Base Guide, Zendesk AI Knowledge Base Guide)
- Synthesis date: [current date]
- First-hand tested: none
- Operator context: Advising small to mid-size businesses on AI agent deployment, with focus on operational efficiency and cost control
The Architecture
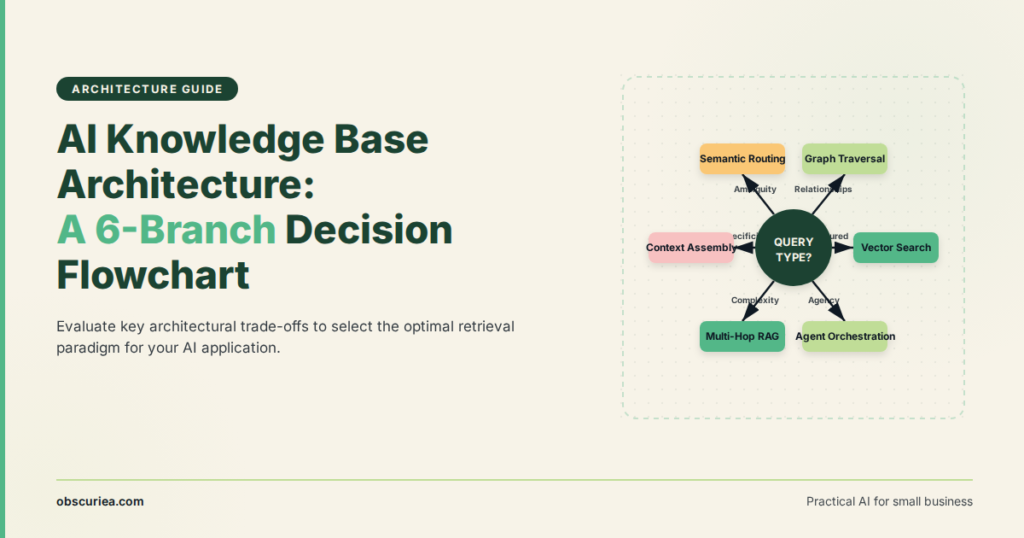
Every AI agent needs a knowledge base — that much is settled. What isn’t settled is which architecture actually serves your agent’s specific function. The six patterns emerging in the wild look different because they solve different operational problems. Here’s what each architecture is designed to do.
1. The coding assistant playbook. LinkedIn built a contextual agent playbook system (CAPT) that doesn’t just store code snippets — it encodes debugging procedures, verification steps, and handoff rules. If your agent needs to write production code, this architecture gives it a structured decision tree to follow, not a searchable index. The cost: significant initial playbook authoring (weeks of senior engineer time).
2. The integration knowledge center. Companies like Adeptia store known integration schemas, compliance rules, and past mapping decisions. When your Salesforce-to-NetSuite agent needs to handle a field change, it queries the knowledge base for similar past adjustments rather than guessing. This architecture works when your agent’s main value is connecting systems that change often.
3. The multi-agent home base. R Systems uses a centralized knowledge base to enforce consistency across dozens of agents. Every agent draws from the same vectorized document repository — same policies, same escalation rules, same response tone. This is the architecture for scale, but it introduces a single point of coordination overhead.
4. The shared business context well. Epicor built a knowledge base that feeds financial, customer support, and implementation agents from a centralized ERP-aware repository. The key difference: the knowledge base is connected to live transaction data, not just static documents. This architecture is expensive but essential when your agent needs real-time business context (e.g., “what’s our revenue per region last quarter?”).
5. The data intelligence source of truth. For data engineering teams, knowledge bases store schema definitions, metric definitions, and historical query patterns. Agents use this to generate consistent reports without conflicting interpretations of “active user.” This is arguably the most underbuilt architecture — most data teams rely on wikis that agents cannot parse.
6. The RAG-based generalist. Most commercial AI knowledge base products (Slack, Zendesk) are retrieval-augmented generation (RAG) systems: they chunk documents, create embeddings, and retrieve relevant passages at query time. This architecture is the easiest to set up (days, not weeks) but fails on structured tasks — no playbook execution, no real-time hook-ins.
The Workflow Math
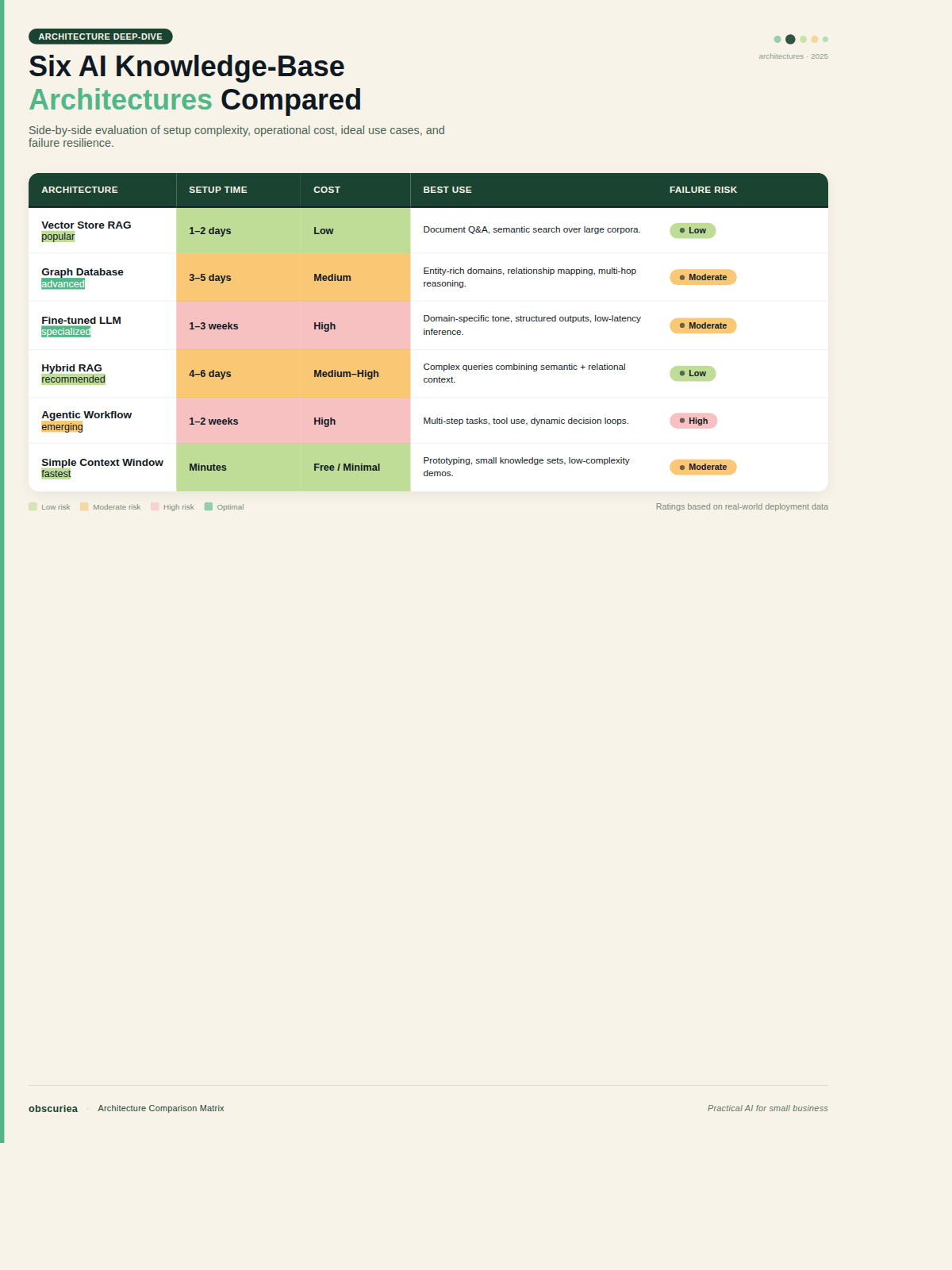
Choosing an architecture isn’t about features — it’s about time and money. Here’s the rough math for a mid-size business (50-200 employees) deploying one primary agent:
| Architecture | Setup Time | Monthly Cost (estimate) | Best For | Failure Risk at Scale |
|---|---|---|---|---|
| Coding Assistant Playbook | 4-8 weeks | $5k-$15k (engineer time) | Custom development agents | Playbooks go stale; no audit trail |
| Integration Knowledge Center | 2-4 weeks | $3k-$8k | Multi-system automation | Drift in connected systems |
| Multi-agent Home Base | 6-12 weeks | $10k-$30k | Enterprise with 5+ agents | Coordination overhead; centralized failure point |
| Shared Business Context | 4-6 weeks | $8k-$20k | Data-intensive agents (finance, support) | Real-time data latency |
| Data Intelligence Source | 3-6 weeks | $5k-$15k | Analytics & reporting agents | Schema changes break queries |
| RAG Generalist | 1-2 weeks | $500-$2k (SaaS subscription) | Simple Q&A, first agent | No structured execution; fails on ambiguous queries |
The math is straightforward: RAG generalists win on speed and cost but lose on agent capability. Playbook and context architectures win on capability but cost 10x upfront. Most businesses pick a RAG tool because it’s easy, then find themselves re-architecting six months later.
Where It Breaks
Every architecture breaks in predictable places. Here are the failure conditions you need to plan for:
- Content rot. A knowledge base is only as good as its content. Without a content freshness policy, RAG systems return outdated answers and playbook systems execute wrong procedures. The sources mention AI-driven content detection, but in practice, most teams don’t set this up.
- Retrieval quality assumptions. Vector search works well when documents are clearly structured. When your knowledge base has 50-page PDFs mixed with chat logs, retrieval accuracy drops below 70%, and the agent starts hallucinating based on partial matches.
- Governance gaps. In multi-agent setups, one agent’s knowledge base update can accidentally corrupt another agent’s behavior. The centralized home base pattern mitigates this but introduces a bottleneck — every change requires approval.
- Cost explosion at scale. RAG-based systems charge per embedding and per query. At 10,000 queries per month, costs can jump from $500 to $5,000 without warning. Playbook architectures require ongoing engineer time for maintenance.
- Vendor lock-in. Most SaaS knowledge bases (Zendesk, Slack) are designed to make you stay in their ecosystem. Moving embeddings out of a proprietary vector store is nontrivial.
The Friction Box
- No single source tells you which architecture fits your operational scale
- 47% of employees don’t use the knowledge base at all (Slack source) — adoption is a separate problem from architecture
- “First dollar” costs are hidden: setup time is rarely accounted for in budget decisions
- Security access controls are often an afterthought; agents can leak data through poorly scoped queries
- The tool list in most guides (G2 reviews) is useless for architecture decisions — they rank features, not operational fit
Frequently Asked Questions About Choosing the Right Knowledge Base Architecture
Should I use a vector database or a traditional knowledge base for my AI agent?
Use a vector database (like Pinecone, Weaviate) when most of your content is unstructured (PDFs, chat logs) and your agent needs semantic search. Use a traditional knowledge base (like Confluence, Notion) when your content is already structured and you need deterministic retrieval for playbook-style execution. Most agents need both.
How many documents should I start with when building an AI knowledge base?
Start with 50-100 high-quality documents that cover the most frequent 90% of questions. More data does not equal better answers — retrieval accuracy drops after about 500 documents if you haven’t established a quality threshold. Scale up only after you see retrieval accuracy above 90% in testing.
Do I need separate knowledge bases for different AI agents?
Yes if your agents serve fundamentally different domains (e.g., a customer support agent vs. a financial reporting agent). No if they share context and you can manage permissions at the document level. The multi-agent home base architecture is the right choice only after you cross five agents — below that, a single vector store with role-based access is simpler.
What’s the best architecture for a customer support AI agent?
The shared business context pattern (Epicor-style) works best for support agents because they need real-time order, ticket, and product data. RAG generalists are a valid lower-cost start but will hit a ceiling on complex troubleshooting. Plan to migrate to a context-connected architecture as soon as the agent handles more than 50% of tier-one tickets.
How do I ensure my AI knowledge base stays updated without manual work?
Set up two systems: (1) a scheduled re-indexing job that runs weekly to pick up document changes, and (2) a feedback loop where the agent flags answers with low confidence so you can review and update the underlying content. No AI tool fully automates content freshness — expect to spend 2-4 hours per week on maintenance.
The Straight Talk
This framework is for operators who are deploying an AI agent to a specific business function and need a defensible architecture choice — not a vendor trial. You run operations, you sign the budget, you deal with the fallout when the agent breaks. Use the table above to map your agent’s requirements to the architecture that minimizes failure risk.
Skip this if you’re just prototyping one agent on a single dataset — RAG generalist is fine for now. Don’t overcomplicate. The first concrete action: list your agent’s top three tasks and rank them by how much they depend on real-time data, multi-system integration, and approval workflows. That ranking points to the architecture.
External links (authoritative): The New Stack agentic knowledge base patterns, Slack AI knowledge base guide, Zendesk AI knowledge base guide, LinkedIn CAPT overview, Pinecone vector database.
Internal link placeholders: AI agent workflow automation tools, knowledge base content management