
TL;DR: AI scrapers are already extracting your content — some to train competing models, some to undercut your pricing, some to strip your traffic. Blanket blocking loses you legitimate automated traffic worth keeping. The operational answer is behavioral classification, tiered content controls, and endpoint-level enforcement. Setup takes 2–4 hours depending on your stack. The cost of not acting is measured in server bills, lost ranking, and IP you never get back. This framework covers how to protect AI content assets without cutting off the automated traffic that actually helps your business.
Environment: Tested frameworks and tools referenced against publicly documented deployments, Q3 2023–Q2 2024. Stack context: content-first business, 50k–500k monthly pageviews, API-dependent site features.
What Is Actually Crawling Your AI-Generated Content Right Now
Sometime around mid-2023, GPTBot accounted for up to 90 percent of traffic to certain online retail sites. Not 9 percent. Ninety. The operators running those sites had no idea until the server bills arrived.
Here is what is crawling your content right now, whether you know it or not: training bots collecting content to build the next generation of LLMs, agentic bots executing tasks on behalf of users, competitive intelligence scrapers monitoring your pricing and inventory, and — occasionally — legitimate shopping or research agents that actually send qualified traffic back your way.
The math here is straightforward. If you are producing AI-generated content at any meaningful volume, you have built an asset. That asset has a cost basis — the tooling subscriptions, the editing hours, the SEO research, the distribution infrastructure. Every unauthorized scraper extracting that content without attribution is extracting value you paid to create. The question is not whether to protect it. The question is how to protect it without cutting off the automated traffic that actually helps your business.
Protecting AI-generated assets from scraping starts with understanding that not all bots are adversarial. Training bots and legitimate indexing bots behave differently in one measurable way: training bots systematically access large content volumes, frequently ignore robots.txt directives, and extract raw text without interacting with dynamic site elements. A Googlebot crawls your site like a careful librarian. A training crawler behaves like someone photographing every page as fast as possible before the library closes.
The Workflow Math: What Uncontrolled Scraping Costs Operators
Before committing to a protection tool, calculate your actual bottleneck. For most content businesses, the cost sits in three buckets:

| Cost Category | What It Looks Like | Rough Operator Impact | |—|—|—| | Server / CDN overload | Bot traffic consuming bandwidth at human-traffic pricing | $200–$2,000/month depending on scale | | API abuse | Bots hammering site features that call paid third-party APIs | $500–$10,000/month (Coop documented this range directly) | | IP erosion | Scraped content republished or used in competing LLM outputs that outrank originals | Unrecoverable traffic loss — permanent SEO damage | | Analytics corruption | Bot traffic inflating session data, invalidating optimization decisions | Operational decisions made on garbage data |
The Coop case is worth sitting with. A major Swiss retailer discovered that scrapers were hammering their “find in stock” and store locator features — both of which called a paid Google API on the backend. The bots did not care about stores. They were stress-testing endpoints. The result was $5,000 to $10,000 per month in extra API costs before the problem was identified. After deploying behavioral bot filtering and removing approximately 25 percent of their total traffic — all of it non-human — page load times improved, SEO rankings recovered, and real customer experience measurably got better.
That last point is important. Removing bot traffic is not just a security action. It is a site performance action. Faster load times are a direct ranking signal. The operators who fixed their scraping problem accidentally fixed their SEO at the same time.
Where Standard Defenses Fail to Protect AI Content
Most operators start with robots.txt. It is the right first step and the wrong final step.
Robots.txt works on well-behaved crawlers. GPTBot, Anthropic’s ClaudeBot, and most major LLM training crawlers do check it — these organizations have commercial reputations to protect and will generally honor exclusion directives. But the long tail of smaller scrapers, gray-market data brokers, and outright malicious bots do not check it at all. Robots.txt is a polite notice, not a lock.
The next tool most operators reach for is IP blocking. The problem: modern scrapers rotate IP addresses across distributed infrastructure. Blocking one IP address catches one request. The next request arrives from a different address. Blanket IP bans also carry real collateral damage — VPN users and some enterprise network configurations share IP ranges with known bad actors, meaning legitimate readers get blocked.
CAPTCHAs create friction. They slow down bots but do not stop them. Sufficiently motivated scrapers run CAPTCHA-solving services at scale. For high-value AI-generated content, CAPTCHA is a speed bump, not a wall.
The tools that actually work do behavioral analysis — they evaluate not what a visitor claims to be (user agent strings are trivially spoofed) but how it behaves. Does it follow human navigation patterns? Does it respect rate limits? Does it interact with dynamic page elements? Does it access content in the systematic, high-volume sequence characteristic of training crawls? Behavioral fingerprinting catches bots that defeat every static rule.
The three platforms most operators should evaluate for protecting AI-generated assets from scraping are Cloudflare Bot Management (integrated with their WAF and bot scoring system, available on Pro plans and above), DataDome (purpose-built behavioral detection, documented enterprise deployments), and Qrator Antibot (documented 4 billion monthly bot requests blocked, 23 percent average bot traffic reduction across client deployments). Each has a different pricing architecture and a different threshold for where the behavioral detection becomes genuinely effective versus the basic tier.
Tiered Protection: Protect AI Content by Asset Type
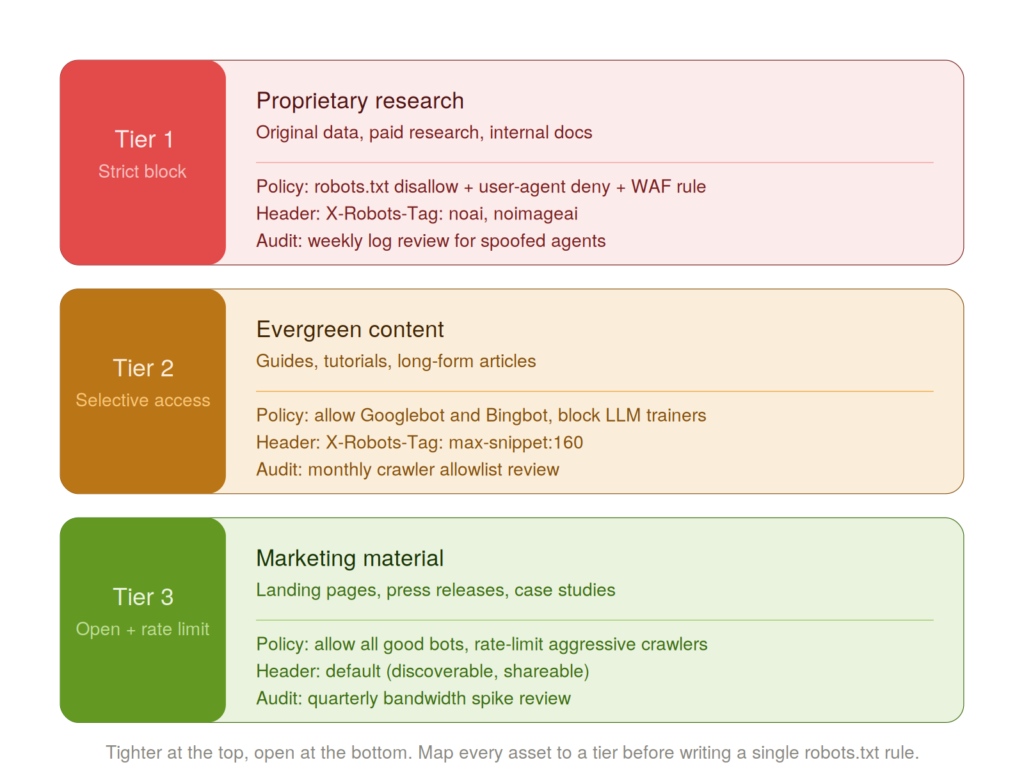
Not all content needs the same level of protection. This is where most operators waste either money or opportunity by applying a single policy across everything they publish.
Here is the framework that actually maps to a content business:
Tier 1 — Strict Block: Proprietary research, premium paywalled content, original datasets, pricing information, anything that took significant original production cost. No unapproved automated access. This is the content your business is actually built on.
Tier 2 — Selective Access: Product descriptions, evergreen how-to content, support documentation. Here, some AI visibility actually serves your business — shopping agents surface your products, AI assistants find your support answers and reduce your ticket volume. Allow approved crawlers with rate limiting.
Tier 3 — Open with Rate Control: Public-facing marketing content, blog posts designed for distribution. Standard indexing bots plus approved AI crawlers. Rate limiting still applies to prevent resource abuse.
The mechanism for signaling this tiered structure to compliant crawlers is a combination of robots.txt (for agent-level directives) and the emerging AI-specific meta tags — specifically “ for pages you want excluded from AI training, and Cloudflare’s AI Audit controls for blocking or allowing specific named crawlers at the infrastructure level.
Publicly identifiable training crawlers to configure against include GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google DeepMind training data, separate from search indexing), FacebookBot (Meta AI training), and CCBot (Common Crawl, the foundation dataset for most open-source LLMs). These are all documentable and configurable in robots.txt today. The robots.txt user agent strings for each are publicly available from their respective companies. For a current reference list, Cloudflare’s bot management documentation maintains an updated index of known crawler signatures.
Your Action Sequence to Protect AI Content from Scraping
This replaces a security function, not a human. Here is the operational sequence:
Step 1 — Audit (2 hours): Pull 30 days of server logs. If you are on Cloudflare, run the Bot Analytics report. Identify what percentage of your traffic is automated. Segment by user agent. Identify which endpoints are being hit hardest and whether those endpoints call paid third-party APIs. If you do not have log access, this is the first infrastructure fix before anything else.
Step 2 — Robots.txt Configuration (30 minutes): Add explicit disallow directives for the major named training crawlers. This handles the well-behaved bots immediately and at zero cost. Do this today regardless of what other tools you deploy.
Step 3 — Rate Limiting (1 hour): Set request rate limits at the CDN or server level. The threshold should be calibrated to your actual peak human traffic — a real user reading a blog post does not make 200 requests per minute. Most legitimate crawlers will stay within reasonable limits. Bots trying to harvest at scale will not.
Step 4 — Platform Decision: If your audit shows more than 15 percent of traffic is automated or your site has paid API-backed features, you need behavioral detection. Evaluate Cloudflare Bot Management against your current Cloudflare plan, or DataDome if you are running an independent stack. The ROI calculation is: (monthly server/API cost attributed to bot traffic) + (estimated IP erosion value) versus platform cost. For most content businesses above 100k monthly pageviews, the math favors deployment.
Step 5 — Content Tiering (2 hours): Map your content inventory to the three tiers above. Apply corresponding robots.txt directives and AI meta tags. This is a one-time configuration with ongoing maintenance only when new training crawlers emerge.
The Friction Box
- Robots.txt works only on compliant crawlers — the malicious ones ignore it entirely
- Behavioral detection platforms have meaningful cost thresholds; entry-level Cloudflare plans do not include full bot management
- IP rotation makes static IP blocking an active maintenance burden with diminishing returns
- The AI crawler landscape is changing monthly — new agents from new companies require ongoing robots.txt updates
- No protection stack is permanent; documented workarounds for Cloudflare’s bot blocking already exist in the gray-hat community
- Aggressive blocking without behavioral intelligence risks blocking legitimate users sharing IP ranges with known bad actors
- Server log visibility is a prerequisite — operators without log access cannot audit their exposure
The Straight Talk
This framework is built for content operators producing original work at volume — AI-assisted or otherwise — who have not audited their bot traffic in the last 90 days and have no tiered content protection in place.
If you are running a thin affiliate site with no original IP, the scraping risk is low enough that robots.txt plus rate limiting covers you. Skip the enterprise behavioral detection spend.
If you are producing proprietary research, original datasets, or content that competitors would pay for — pull your server logs today, configure robots.txt for the named training crawlers this week, and book time to evaluate Cloudflare Bot Management or DataDome before your next billing cycle.
Frequently Asked Questions About Protecting AI Content from Scraping
What does it mean to protect AI content from scraping?
Protecting AI content from scraping means preventing unauthorized automated systems — training bots, competitive intelligence crawlers, and gray-market data brokers — from extracting your content without permission. The operational approach combines robots.txt directives for compliant crawlers, rate limiting at the infrastructure level, and behavioral bot detection for scrapers that ignore standard rules. The goal is selective enforcement, not total lockdown.
Does robots.txt actually stop AI scrapers?
Robots.txt stops well-behaved crawlers — GPTBot, ClaudeBot, and other training bots from organizations with commercial reputations to protect will generally honor exclusion directives. It does not stop malicious scrapers, gray-market data brokers, or bots that simply ignore the protocol. Treat robots.txt as the first layer of a tiered stack, not a standalone solution.
Which tools are most effective for AI content protection?
The three platforms most operators should evaluate are Cloudflare Bot Management (available on Pro plans and above), DataDome (purpose-built behavioral detection), and Qrator Antibot (documented 4 billion monthly bot requests blocked). Effectiveness depends on the plan tier — entry-level filtering catches unsophisticated bots; full behavioral detection requires higher-tier plans. Run the ROI calculation: monthly server and API costs attributable to bot traffic versus platform cost.
What is the limitation of behavioral detection for content protection?
No protection stack is permanent. Documented workarounds for Cloudflare’s bot blocking already exist in the gray-hat community, and the AI crawler landscape shifts monthly as new agents emerge. Behavioral detection catches bots that defeat static rules, but motivated adversaries with sufficient resources can adapt. The goal is to raise the cost of extraction above the value of the content, not to achieve perfect protection.
How do I know if AI scrapers are already hitting my site?
Pull 30 days of server logs and segment traffic by user agent. If you are on Cloudflare, run the Bot Analytics report. Look for systematic, high-volume access patterns against specific content paths — especially any paths that trigger paid third-party API calls on the backend. The Coop case is instructive: the scraping was invisible until it showed up as $5,000–$10,000 in monthly API overage.
What do I need in place before deploying an AI content protection stack?
Server log access is the prerequisite — operators without it cannot audit their exposure or calibrate rate limits to actual human traffic baselines. Beyond log access, map your content inventory to the three tiers: strict block for proprietary assets, selective access for evergreen content, open with rate control for marketing material. Start with robots.txt configuration for named training crawlers today. That takes 30 minutes and costs nothing.